How to Use Lavender's 90+ Email Score Without Letting It Flatten Your Voice
Lavender's homepage now leads with 'your buyers hate AI cold emails.' The fix is to read the sub-scores as structural gates, not a number to maximize - four gating sub-scores, four advisory ones, one rule that keeps your voice intact.
Lavender's homepage now leads with "Your buyers hate AI cold emails. They won't hate Ora's." That's a striking thing for the company most associated with AI-coached sales email to write in May 2026 - and it's a tacit admission that the very thing Lavender helped popularize, the 0-100 email score, has produced a corpus of cold emails that all sound the same.
I think the score is still worth using. The flattening isn't a Lavender problem; it's a score-chasing problem. The fix is to read the sub-scores the way a deliverability engineer reads SpamAssassin - as a checklist of structural gates, not as a single number to maximize. Below: which gates matter, which to ignore, and the one rule that keeps your voice intact.
What the score is actually measuring
Lavender's coach scores emails character-by-character and breaks the 0-100 number into around eight to ten sub-scores. The 2026 Reply.io review lists them as subject line, intro line, body length, readability, question count, personalization, mobile-friendliness, spam triggers, and call-to-action. The vendor's own framing puts emails scoring 90+ at "3x more replies than emails scoring below 50" - a number worth treating skeptically, because the comparison set is "emails Lavender users wrote with the coach turned off," which selects for both worse writers and worse outreach hygiene.
The right move is to split the sub-scores into two buckets. Some are structural - they measure things that genuinely affect whether an inbox provider delivers the message or whether a buyer reads the first line on their phone. Others are advisory - they measure stylistic conventions that correlate with reply rates in Lavender's dataset but compress your differentiation when chased.
The structural sub-scores: treat as gating
Four of the sub-scores are worth treating as hard pass/fail.
Body length under about 120 words. Mobile clients (Apple Mail, Gmail iOS) truncate aggressively; long emails get marked unread and never come back. Lavender's length sub-score caps out around 50-100 words, which is tight, but anything under 120 is fine.
Mobile-friendly opener. The first 50 characters need to survive iPhone preview - which means no "Hope this finds you well" prefix eating the screen real estate. The mobile-readability sub-score catches this and it's worth listening to.
Spam-trigger word check. Lavender flags words like "guarantee," "free," and "act now." After the Gmail and Yahoo bulk-sender enforcement of late 2025, every spam-flag triggered is a real deliverability risk; no slack left to absorb sloppy word choice.
Subject line under about 50 characters. Longer subjects truncate in the inbox list view; Lavender's subject-line sub-score is right to push you shorter.
Pass these four and you can ignore most of the rest. If you've been auditing AI-generated prospect drafts from any of the Breeze-family agents, the same four checks apply - they're the ones the inbox actually cares about.
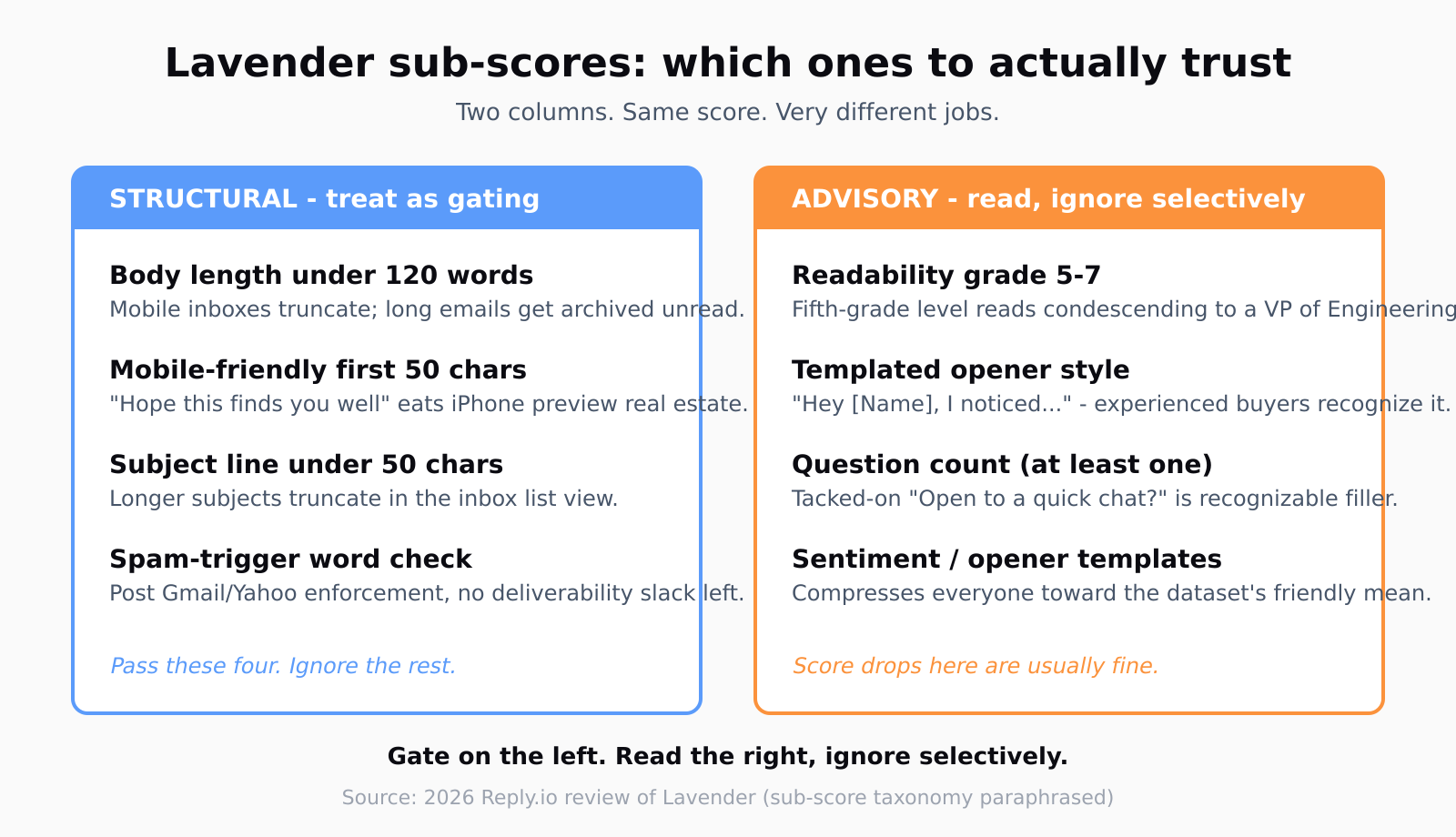
The advisory sub-scores: read, then ignore selectively
The other sub-scores are where the flattening happens.
Readability grade. Lavender rewards a Flesch-Kincaid grade of 5-7, roughly "a fifth grader could read this." That's defensible for a generic prospect but actively wrong for technical buyers. A VP of Engineering reading an email written at fifth-grade level reads it as condescending; she expects you to talk to her at her level. The cost of pushing the grade up to 9 or 10 is maybe a five-point Lavender hit, and you should take it every time when the recipient is technical.
Opener templates. The coach nudges you toward "Hey [Name], I noticed [Trigger]" openers. They score well because Lavender's training set is biased toward openers like that, but experienced buyers recognize them - and recognition is the first step toward archiving the email. I'd rather open with a specific noun ("Your last earnings call mentioned ARR was up 19%...") than a templated greeting that signals "this is sequence number 4 from a tool."
For reps who already write strong emails, the suggestions can feel prescriptive or generic rather than genuinely insightful. The initial drafts were a bit robotic and tended to stitch points together almost verbatim. [...] over-reliance on its AI writing features can produce generic copy that undermines the personalization it's designed to enable.
That's from the 2026 Reply.io review - a vendor competitor, so take it with a pinch of salt, but the criticism matches what I hear from reps who've used the tool for more than a quarter.
Question count. Lavender wants at least one question per email. Fine in theory; in practice this is where reps tack on "Open to a quick chat next week?" to every send and the score goes up while the read-through rate goes down, because the question is recognizable filler.
The one rule: hold one persona-anchored detail per email
Here's the heuristic that keeps score-chasing from compressing your differentiation. Every email contains at least one specific detail that could only have been written about this recipient, and that detail does not get cut for length, readability, or opener-template reasons. The detail can be a quoted phrase from their recent earnings call, a specific repo they starred last week, a named teammate they hired, a city they just opened an office in. Cut anything else first.
If the score drops from 92 to 87 because that detail is one sentence longer than the template wants, you accept the 87. The flattening always happens at the boundary where you trade specificity for readability - refusing that trade once per email is the whole game. This is why I've argued separately that the real reply-rate lift comes from stacking three or more buying signals per send: the signal is the detail; the score just measures the wrapper around it.
The same logic generalizes across the wider AI SDR tooling landscape - every agent that scores or critiques drafts has the same shape, and the same fix. The structural feedback is real; the stylistic feedback is the sound of the dataset's mean.
This is exactly the seam Leadex is built to close: the score is downstream of who you're writing to, and "who" is where the differentiation actually lives. A chat-native research agent that produces a CSV with company, role, and a timestamped signal per row gives you the persona-anchored detail to write around. Lavender's score will tell you whether the wrapper is readable; only the prospect list can tell you whether the email has anything specific to say.
And on the Ora rebrand - Lavender's bet seems to be that the way out of AI-flattening is more AI (!), tuned to the individual rep's historic emails. Maybe it works. (I believe the structural problem is upstream of the tooling, but the experiment is worth watching.)
FAQ
Should I always aim for a Lavender score above 90?
No. Aim for 80+ with the structural sub-scores green: length, mobile-friendliness, spam triggers, subject line length. Above 80, every point you push toward 100 typically costs one specific detail. Hold the detail.
Which Lavender sub-scores actually correlate with reply rate?
The structural ones - length, mobile-friendliness, spam triggers, subject line length. The readability grade and opener template sub-scores correlate in Lavender's internal dataset, but that correlation reflects the dataset's bias toward templated openers, not a universal truth about your buyers.
Is Lavender worth it for an experienced SDR?
Probably yes for the structural gating; probably no for the stylistic suggestions. Most experienced reps end up using it as a deliverability check after writing the email in their own voice. The free tier of five emails per month is enough to calibrate where your existing emails land before deciding.
What about the new Ora assistant?
Ora drafts whole emails from CRM context rather than scoring drafts you wrote. It's a different product shape - closer to HubSpot Breeze than to the original Lavender coach. The flattening risk shifts: instead of compressing your voice toward the score's mean, Ora compresses toward your team's historic email patterns. Whether that's better depends on whether the team's existing voice is the one you want to scale.