What Autonomous AI SDRs Still Cannot Handle in 2026
Autonomous AI SDRs hit a wall on timing, stakeholders, brand at volume, and replies. The human-in-the-loop pattern that out-performs both pure autonomy and an all-human floor.

The autonomous AI SDR thesis was that you could fire the human, install Alice or Ava, and watch qualified pipeline appear. Two years in, the thesis is bruised. Companies that wrote the cheque are coming back to LinkedIn to say it did not work, the meetings booked were of the wrong kind, and the reps they laid off in 2024 are quietly being rehired in 2026 - just with different titles and a thinner remit.
This is not a category obituary. The category is growing. Fortune Business Insights still puts the AI SDR market at $4.27 billion in 2025, projected to hit $5.22 billion this year and $24.32 billion by 2034 at a 21.2% CAGR. The autonomous tier inside that category is the part that is hitting a wall, and the human-in-the-loop tier is the part still compounding. It is worth being precise about what stopped working and why, because the hangover is real and the lessons are useful.
The clearest framing of the split comes from Anterion's AI SDR Wars teardown:
The AI SDR label is doing a lot of work in 2026. It covers two fundamentally different product categories that happen to share a name. The first is the autonomous agent play: tools like 11x.ai and Artisan AI that market themselves as direct headcount replacements [...]. The second is the augmentation play: platforms [...] that position AI as a force multiplier for existing sales teams rather than a substitution. These are not the same product.
Below is the list of things autonomous AI SDRs still cannot handle in 2026, drawn from teardowns, G2 reviews, and the LinkedIn confession posts of buyers who paid for them. Followed by the human-in-the-loop pattern that out-performs both pure autonomy and the old all-human floor.
What autonomous AI SDRs still cannot do reliably
The honest list, four items long, is the one nobody puts on a vendor landing page.
First, timing judgement. A signal fires - somebody downloads a whitepaper, a champion changes jobs, a competitor lays off engineers - and the question is whether to reach out today, in two weeks, or never. The model has no taste for this. It treats every fired signal as an actionable one, which produces the "37 emails arrived in my inbox the morning after we announced our Series B" pattern that founders started posting screenshots of in late 2025. The human SDR sat on the signal for two days, watched what other vendors were doing, and reached out on a Tuesday with a sentence that did not start with "Congratulations on the recent funding."
Second, stakeholder awareness. Autonomous agents have a contact record. They do not have a relationship map. A model writing to a procurement lead at an account where her CFO is already in a paid pilot does not know to soften the pitch, and the procurement lead reads the email as a vendor who did not bother to check the existing relationship. The reputational cost is borne by the vendor, but the model never sees it. There is no feedback loop.
Third, brand stewardship at volume. The Anterion teardown lands this point cleanly: "Buyers with budgets above $50K annually want human-AI hybrid models with accountability. Buyers under $20K annually want transparent pricing and fast setup. The middle is collapsing." Sending 200 high-quality emails per day is one problem. Sending 50,000 generic-but-personalized emails per day across a 25-domain sending stack and not destroying the brand is a different problem, and it is the problem that has produced the loudest post-purchase regret in the category.
Fourth, reply handling. The pitch of an autonomous SDR is that it books the meeting, not just queues the touch. Reply handling is where this pitch breaks. A model that nailed the opener can still misread an out-of-office, a "not me, but try Sarah" handoff, or a polite "send me a deck and I will circulate." The bookings dashboard shows green; the qualified pipeline does not move. Buyers of 11x.ai Alice have been the most public about this specific failure mode, but it is not unique to that product.
Why the human-in-the-loop pattern outperforms both extremes
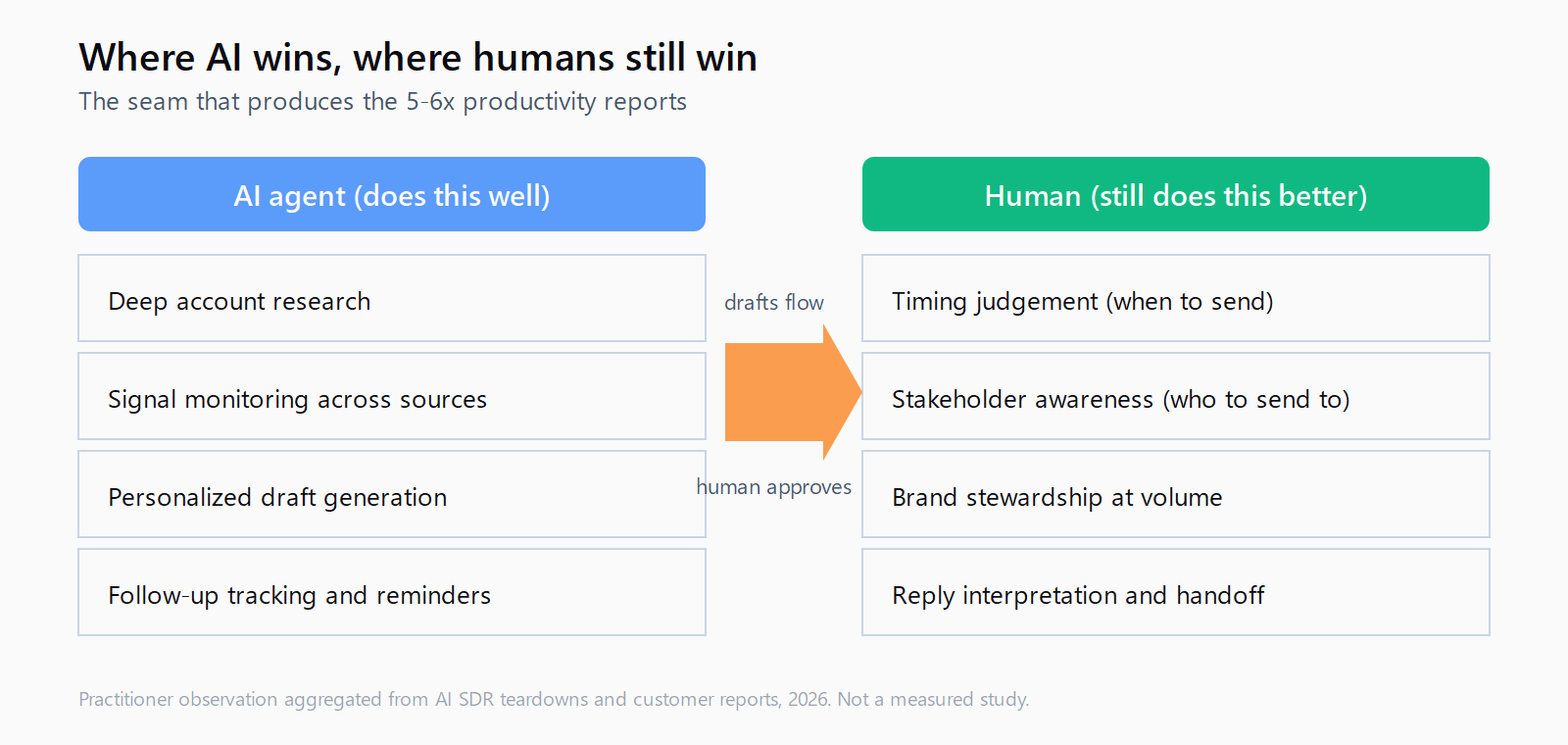
The pattern that wins in 2026 is not "AI does everything" and not "humans do everything." It is a deliberate split where the model handles the work it is genuinely better at - account research at scale, signal monitoring, draft generation, follow-up tracking - and the human keeps the judgement calls. Reach out today or wait? Send to this contact or escalate to her boss? Take the warm reply or sit it out because the timing is wrong? Those stay human.
Regie.ai's growth story is the cleanest data point on this thesis. ARR up 300% year-over-year, $30 million Series B closed in early 2025, customers like Crunchbase and Copado, and a product priced at $35,000 per year for the AI Agents tier - above some autonomous offerings, sold on the argument that "autonomous AI without human oversight produces spam at scale." Buyers who tried the pure-autonomy tier and felt the meeting-quality drop are the ones writing the cheques.
The discipline is the same one I have argued for in signal-stacking outbound workflows: one trigger is never enough, and one mode of automation is never enough either. The model and the human are stacked the same way two signals are stacked. Either alone is brittle. Together, the false-positive rate drops by a useful amount.
The configuration the winning teams actually run
The pattern that produces the reported 5-6x productivity gains over pure autonomy is not a product. It is a configuration. Three pieces.
Piece one: research is automated, exhaustively. The AI runs deep account research before any touch goes out - last funding round, hiring posture, tech stack moves, executive job changes, customer count - and assembles a brief the human reads in ninety seconds. This is the part autonomous tools also do, and it is also the part they do best.
Piece two: drafts are generated, never auto-sent. The model writes the opener, the follow-up, and the reply suggestion. The human reads each one, edits roughly a third, kills the ones the model got wrong, and approves the rest. The volume goes up because drafting time disappears. The quality does not collapse because the human is still the last gate.
Piece three: replies are routed to humans. The model can suggest a reply, but the human sends it. This is the piece that breaks the autonomous flow and the piece that the hybrid teams insist on. A model that mistakes "send me a deck and I will circulate" for "let's book a meeting" books a meeting nobody attends, and the cost of that no-show on the calendar is higher than the cost of a human reading the thread for ten seconds.
This is the same shape Leadex ships at the discovery end of the funnel: the agent drafts a research plan, the human approves it before the agent touches the web, and the CSV that lands in the CRM carries URLs and timestamps per row so the reasoning is auditable. The plumbing is the same. The pattern is research and drafts done by the model, decisions and dispatch done by the human. Different surface, identical principle.
How to budget against the autonomous-versus-hybrid tradeoff
If your outbound motion is already proven - your ICP is clear, your messaging converts, your deal economics absorb the tooling cost - autonomous agents at $5,000 to $15,000 per month can scale your pipeline capacity without scaling headcount. If you are still figuring out messaging, autonomy is the worst possible choice; it personalizes the wrong sentences at the wrong people at the highest possible velocity.
If you are mid-funnel - you know your ICP but the messaging is fragile - the human-in-the-loop tier at the $35,000-per-year price point is where the survival rate is highest. The human catches the messaging mistakes the model would have shipped at scale.
If you are early - first ten reps, messaging still in flux - skip both tiers. Run a Clay-plus-Instantly stack at a fraction of the cost, hire one good SDR, and revisit when the motion is stable. The autonomous vendors have made it very expensive to learn what your messaging should be.
FAQ
Did fully autonomous AI SDRs actually fail?
Not commercially - the category is still growing. They have largely failed against the original pitch, which was full headcount replacement. Companies that fired their SDR floor and bought Alice or Ava are the ones reporting the loudest disappointment. Companies that paired autonomous tools with a smaller human team kept the spend and reported better outcomes.
What is the productivity gain from human-in-the-loop vs. fully autonomous?
Multiple independent reviews put the productivity gain for hybrid teams at 5 to 6 times the pure-autonomy baseline. The gain comes from the model handling research, drafting, and signal monitoring while humans keep timing and reply decisions. The exact multiplier varies by motion; the directional finding is consistent across published comparisons.
Are 11x.ai and Artisan AI going to survive consolidation?
The likely outcome is acquisition rather than independent scale. HubSpot Ventures already participated in Artisan's Series A; Salesforce has Einstein SDR in market. The autonomous-agent vendors built features the platform vendors want to bolt onto an existing enterprise book of business. Independent survival as standalone autonomous-SDR companies is the less likely path.
Should I cancel my AI SDR contract if the meetings booked are not closing?
Not before auditing the configuration. Most "AI SDR booked bad meetings" problems trace to a too-broad ICP definition, a missing reply-handling step, or a signal source that is firing on irrelevant triggers. The pattern is to audit the inputs before blaming the model. If the inputs are clean and the meetings still do not close, the autonomous tier is not the right product for your motion - move to the hybrid tier.
How do I know if my motion is ready for autonomy?
Three signs: your messaging has been tested at human-SDR scale and the reply rate is stable; your ICP is narrow enough that personalization templates do not require hand-tuning per account; your reply-handling playbook is documented well enough that a model can follow it. If any of those is missing, autonomy will amplify the gap, not close it.